

Introduction
This project contains the following key points:
1. With the main goal of "helping relieve the stress problems faced by NYCU students", we aim to build a chatbot for mental health support.
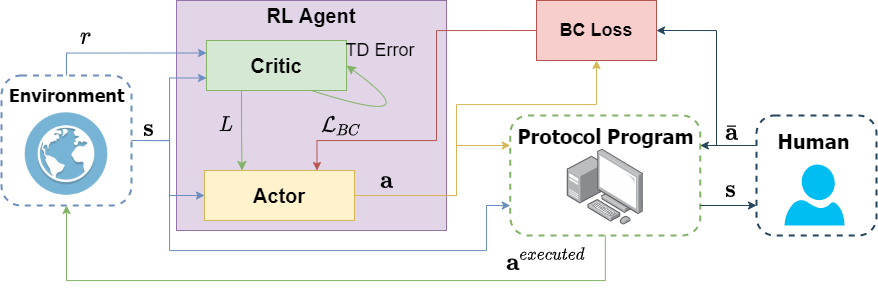
2. The constructed prototype of the dialogue model for mental health support will integrate rule-based functions and learning-based components: it will cover all user input while making it controllable.
3. The interactive dialogue data between users and the system will be collected through the designed dialogue system, and the dialogue data will be sorted and marked by cooperating with the professional team of psychological counseling.
4. The designed dialogue system could use both voice and text as its inputs, which is different from many previous works: through voice input, the system will have higher flexibility in different application scenarios.
5. Add virtual characters to the user interface: Increase the realism and fun of interacting with the chatbot to increase the willingness of users to participate.
6. The robust system that can deal with noise and diverse input data: by training a natural language understanding module (NLU) with a large number of adversarial examples, the dialog manager could provide correct decisions in complex situations.
7. Another perspective on solving the problem of posterior collapse in natural sentence generation will be presented: by adjusting the specification of the flow model, we could decide the KL divergence between the prior and the posterior to provide greater flexibility than previous works.
8. Bilingual dialogue system: It can operate between English and Chinese through the data in the MultiWOZ and CrossWOZ datasets.
9. In this project, we will collect relevant dialogue data for subsequent training of the model. The quality of the dataset is one of the important factors affecting the performance of deep learning models, so we refer to the previous paper Sugariness prediction of Syzygium samarangense using convolutional learning of hyperspectral images, published in the top journal Scientific Reports, which uses deep learning algorithms method to analyze the spectrum of hyperspectral images in fruit trees. The Brix value of the predicted fruit tree fruit is output through regression analysis. During the collection process, it is necessary to pre-treat the collected fruits by returning to temperature. The fruit is sliced, and hyperspectral data of the fruit are obtained using a hyperspectral instrument. Its data collection and processing procedures will be adopted in the subsequent data set creation procedures.
