語音基礎模型及其性能基準工作坊

- 隨著人工智慧不斷發展,基石模型已經成為焦點,並在計算機視覺(CV)和自然語言處理(NLP)領域中發揮至關重要的作用。這些模型包括在NLP領域中的BERT和GPT,以及在CV領域中的SimCLR和BYOL,它們顯著提升了機器學習在這些領域的能力。在語音的領域中,我們也觀察到了這些基石模型在各種任務上展示了卓越的能力。許多學術活動中都有響應對於基石模型的關注, 例如 NeurIPS 2020、AAAI 2022 和ICASSP 2023的研討會都對這些模型的潛力表示了樂觀的反饋。
在這種勢頭上,此研討會將聚焦在:語音基石模型的基準(Benchmark)。這些基準被用來評估語音基石模型的性能。SUPERB 和 SUPERB-SG 測量了各種語音任務,而SLUE 專注於口語語言理解。然而,這些基準主要限於英語。為了促進更全面的分析,LeBenchmark 和 IndicSUPERB 分別評估了法語和印度語的基石模型。XTREME-S 和 ML-SUPERB 在超過100種語言上評估基石模型。值得注意的是,還存在一些正在發展中的基準,包括用於視聽 (audio-visual) 基石模型和指導微調 (instruction-finetuning) 基石模型的基準。改進這些基準仍然需要一個充滿活力且持續進行的對話。
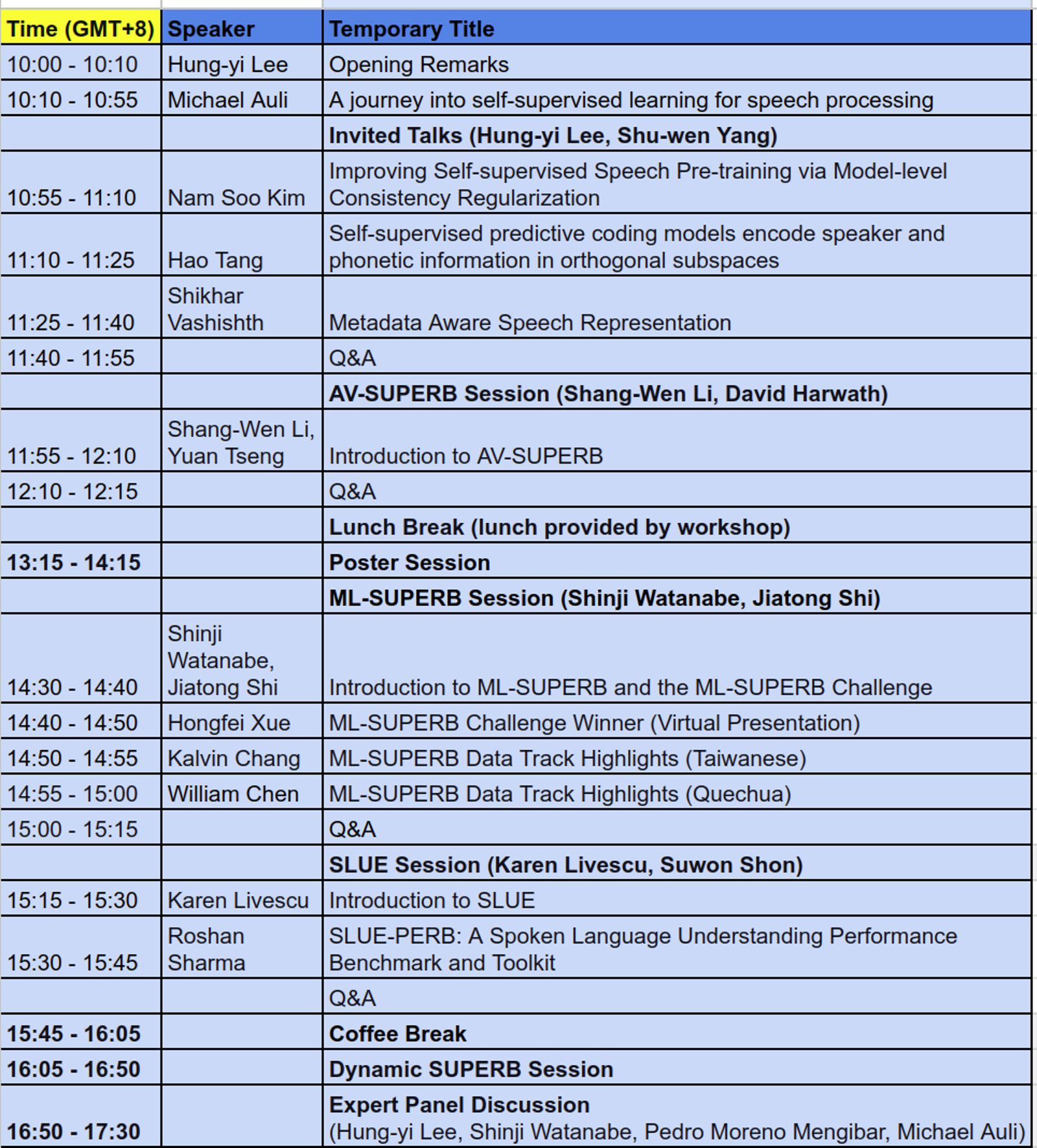
Agenda:
- ASRU衛星研討會「語音基礎模型及其性能基準工作坊(SPARKS)」
- 活動日期:2023年12月16日
- 活動方式:實體會議
- 活動地點:台北市北投區奇岩路一號 台北市北投區大地酒店(7F) 環景宴會廳
- 活動官網: 點擊連結